


在刚刚过去的3月21日,英伟达如期举办了今年的GTC大会(全称为GPU Technology Conference),作为英伟达主办的最重要的 GPU 技术交流活动,从 2019 年开始每年举办一届。在本次大会上,英伟达CEO 黄仁勋就目前大热的生成式AI做了题为《切勿错过 AI的决定性时刻》的主题演讲,同时发布了英伟达为ChatGPT专门研发的全新超高性能GPU——NVIDIA H100 NVL。

NVIDIA H100 NVL
01
在AI领域所向披靡的英伟达
许多读者了解英伟达是在其游戏GPU领域,GTX、RTX系列显卡对于广大消费者来说已经是相当熟悉了,但本次大会的重点似乎是AI领域,难道看到近期 AI 大火后也要来分一杯羹了?实则不然,英伟达与AI可以说有着相当深的渊源,实际上自2012年,在深度学习框架刚刚提出的伊始,AI便与英伟达绑定在了一起,当时,Alex Krizhevsky、Ilya Suskever,以及 Hinton 在英伟达的显卡 GeForce GTX 580 上使用了 1400 万张图完成了训练,可处理 262 千万亿次浮点运算。而十年之后,生成式AI里程牌式的模型Transformer横空出世,OpenAI团队就是使用了英伟达提供的GPU A100训练AI,由此,创造出了令全世界震惊的目前最强AI——ChatGPT。
可以说,没有英伟达强悍的硬件支持,那么就不会有今天的ChatGPT,这个被称为“下一次工业革命元年”的2023年,不知要推迟多久才能到来。在本次英伟达GTC大会上,英伟达CEO黄仁勋难掩其激动的心情,连连重复了三遍:“我们正处于 AI 的 iPhone 时刻!”。是的,对于手中拥有A100和H100两款市面上独一无二的超级“核弹”来说,ChatGPT的空前成功,已经让英伟达“赢麻了”。万人空巷的ChatGPT已经让英伟达的股价又一次坐上了火箭,市值直接增加 700 多亿美元,目前,英伟达市值为 6400 亿美元。数钱数到手软的黄仁勋也是放出豪言:英伟达就是要做 AI 圈的台积电!

难掩喜悦的英伟达CEO黄仁勋
要知道,两年前英伟达推出的A100其性能到现在也没有对手,而去年GTC 2022所推出的H100更是一下子将最强GPU的标准整整提升了3倍!而本次GTC所推出的H100至尊版(H100 NVLINK)更是能将生成式AI(ChatGPT)的算力、提速 10 倍。可以说在AI计算上,英伟达所提供的硬件已经完全垄断了市场,其他厂商短期内难以望其项背。
02
为ChatGPT而生的专用“核弹”
本次大会所推出的重量级产品H100 NVLINK是专门针对大型语言模型训练(LLM)设计,其搭载了两个基于Hopper架构的H100芯片,顶部配备了三个NVLink连接器,使用了两个相邻的PCIe插槽。其FP64计算性能为134 teraFLOPS,TF32计算性能为1979 teraFLOPS,FP8计算性能为7916 teraFLOPS,INT8计算性能为7916 teraFLOPS,是H100 SXM的两倍。其具有完整的6144位显存接口(每个HBM3堆栈为1024位),显存速率可达5.1Gbps,意味着最大吞吐量为7.8GB/s,是H100 SM3的两倍多。
基于此英伟达推出了DGX AI超级计算机,DGX配有8个H100 GPU模组,同时H100配有Transformer引擎,能够处理ChatGPT这样令人惊叹的模型。8个H100模组通过NVLINK Switch彼此相连,实现了全面无阻塞通信。8个H100协同工作,就像是一个巨型的GPU。H100 NVL这样的GPU,其应用无疑可以给AI的迭代进化带来更大的便利:
首先
超高性能的GPU可以加速训练速度,这使得研究人员和开发者能够更快地训练出更加复杂的模型,从而推动AI的发展。
其次
随着AI应用领域的不断扩展,处理的数据量也越来越大,而GPU的发展能够处理大规模数据,并且在数据处理和分析中拥有更快的速度,因此能够有效地处理大量的数据。
再次
由于GPU的高速计算能力,研究人员和开发者能够更加深入地优化模型,进一步提升模型的性能和精度。
最后
GPU的高速计算能力使得AI在各种应用场景中都得到了广泛的应用,如自然语言处理、计算机视觉、语音识别等领域。这些应用的发展离不开GPU的助力。
英伟达十几年前就看到了AI在未来的潜力并一直在加速计算领域深耕,对此黄仁勋总结道:“短短十几年,我们就从识别猫,跨越到了生成在月球行走的太空服猫的过程。现在完全可以说,生成式 AI 就是一种新的计算机,一种可以用人类语言进行编程的计算机。”
03
计算光刻将提速40倍
本次GTC大会,英伟达还带来另一项革命性的技术,或将大幅提高先进光学光刻机的刻蚀速度,这就是NVIDIA cuLitho的计算光刻库。
英伟达宣布,自己已经于 ASML、台积电及新思科技携手推出了 CuLitho 软件库,能够借助 AI 的能力和学习技术来辅助运算,从而提高半导体的微影技术,让之后的芯片能够拥有更紧凑的晶体管和布线。简单来说,这项技术的应用可以使先进制程芯片的制造速度大幅提升,并且将更加节能。英伟达CEO黄仁勋表示:“计算光刻是芯片设计和制造领域中最大的计算工作负载,每年消耗数百亿CPU小时。而英伟达的新技术最终会应用到计算光刻上,在这项技术的加持下,计算光刻的工作时长能从几周直接降低到八小时左右,效率翻了几番。”
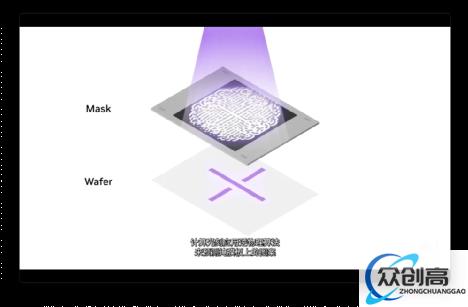
据悉,生产一块NVIDIA H100需要89块掩膜板,在使用传统CPU进行计算刻蚀的时候,处理单个掩模板,需要整整2周时间。而如果在GPU上运行cuLitho则只需8小时即可处理完一个掩膜板。不仅处理速度被大大加快,其需要的功耗也被大幅减低,对此黄仁勋说道:“台积电可以通过在500个DGX H100系统上使用cuLitho加速,将功率从35MW降至5MW。”
04
英伟达不止于此
在英伟达对于未来的规划中,它将参与到AI应用的方方面面,甚至英伟达还计划将AI引入量子计算领域。其推出的L4 Tensor Core GPU,专门针对AI生成视频,其用于加速AI视频,可以提供比CPU高120倍的性能,能效提升约99%。可以优化视频解码与转码、视频内容审核、视频通话等性能,一台8-GPU L4服务器可以取代100多台用于处理AI视频的双插槽CPU服务器;对于静态AI生成图像,英伟达也拿出了对应的L40 GPU,其针对2D、3D图像生成进行优化,并可以结合Omniverse,直接生成3D内容,甚至是元宇宙内容。在未来,英伟达还将推出AI超级云计算,将出租针对AI的算力,让每个企业都可以使用简单的网络浏览器访问AI超算。这是AI的时代,也是英伟达的时代。
05
写在最后
正如此次 GTC 的演讲主题:" 切勿错过 AI 的决定性时刻 ",不管我们目前对 AI 是何看法,但不可否认的是未来 AI 的作用和战略性地位会越来越高。但是目前,我国的AI发展情况不容乐观,加上美国政府对于先进GPU的层层禁令,本次GTC所发布的H100 NVL要想出口给我国可谓是困难重重,顶级硬件的获取受限,这对于本就处于竞争劣势的我国来说无疑是雪上加霜。但是英伟达毕竟是家商业公司,绝对不会放弃中国这个庞大的市场,有业内人士透露,后续英伟达会发布一些阉割特供版(暂定为 A800)给到国内企业。
就目前来看,现在即将来到AI的时代,但更是英伟达的时代。
